- Home
- Machinery Directive
- History of the Machinery Directive 2006/42/EC
- Machinery directive 2006/42/EC
- Whereas of machinery directive 2006/42/EC
- Articles of machinery directive 2006/42/EC
- Article 1 of machinery directive 2006/42/EC - Scope
- Article 2 of machinery directive 2006/42/EC - Definitions
- Article 3 : Specific Directives of machinery directive 2006/42/EC
- Article 4 : Market surveillance of machinery directive 2006/42/EC
- Article 5 : Placing on the market and putting into service - machinery directive 2006/42/EC
- Article 6 : Freedom of movement - machinery directive 2006/42/EC
- Article 7 : Presumption of conformity and harmonised standards - machinery directive 2006/42/EC
- Article 8 : Specific measures - machinery directive 2006/42/EC
- Article 9 : Specific measures to deal with potentially hazardous machinery - machinery directive 2006/42/EC
- Article 10 : Procedure for disputing a harmonised standard - machinery directive 2006/42/EC
- Article 11 : Safeguard clause - machinery directive 2006/42/EC
- Article 12 : Procedures for assessing the conformity of machinery - machinery directive 2006/42/EC
- Article 13 : Procedure for partly completed machinery - 2006/42/EC
- Article 14 : Notified bodies - machinery directive 2006/42/EC
- Article 15 : Installation and use of machinery - machinery directive 2006/42/EC
- Article 16 : CE marking - machinery directive 2006/42/EC
- Article 17 : Non-conformity of marking - machinery directive 2006/42/EC
- Article 18 : Confidentiality - machinery directive 2006/42/EC
- Article 19 : Cooperation between Member States - machinery directive 2006/42/EC
- Article 20 : Legal remedies - machinery directive 2006/42/EC
- Article 21 : Dissemination of information - machinery directive 2006/42/EC
- Article 22 : Committee - machinery directive 2006/42/EC
- Article 23 : Penalties - machinery directive 2006/42/EC
- Article 24 : Amendment of Directive 95/16/EC - machinery directive 2006/42/EC
- Article 25 : Repeal - machinery directive 2006/42/EC
- Article 26 : Transposition - machinery directive 2006/42/EC
- Article 27 : Derogation - machinery directive 2006/42/EC
- Article 28 : Entry into force - machinery directive 2006/42/EC
- Article 29 : Addressees - machinery directive 2006/42/EC
- ANNEX I of machinery directive 2006/42/EC - Summary
- GENERAL PRINCIPLES of annex 1 of machinery directive 2006/42/EC
- 1 ESSENTIAL HEALTH AND SAFETY REQUIREMENTS of annex 1 - definitions - machinery directive 2006/42/EC
- Article 1.1.2. Principles of safety integration of annex 1 machinery directive 2006/42/EC
- Article 1.1.3. Materials and products annex 1 machinery directive 2006/42/EC
- Article 1.1.4. Lighting - annex 1 machinery directive 2006/42/EC
- Article 1.1.5. Design of machinery to facilitate its handling - annex 1 machinery directive 2006/42/EC
- Article 1.1.6. Ergonomics - annex 1 machinery directive 2006/42/EC
- Article 1.1.7. Operating positions - annex 1 machinery directive 2006/42/EC
- Article 1.1.8. Seating - annex 1 machinery directive 2006/42/EC
- Article 1.2.1. Safety and reliability of control systems - annex 1 of machinery directive 2006/42/EC
- Article 1.2.2. Control devices - annex 1 of machinery directive 2006/42/EC
- Article 1.2.3. Starting - annex 1 of machinery directive 2006/42/EC
- Article 1.2.4. Stopping - annex 1 of machinery directive 2006/42/EC
- Article 1.2.4.4. Assembly of machinery - Annex 1 of machinery directive 2006/42/EC
- Article 1.2.5. Selection of control or operating modes - annex 1 of machinery directive 2006/42/EC
- Article 1.2.6. Failure of the power supply - annex 1 of machinery directive 2006/42/EC
- Article 1.3. PROTECTION AGAINST MECHANICAL HAZARDS - annex 1 of machinery directive 2006/42/EC
- Article 1.4. REQUIRED CHARACTERISTICS OF GUARDS AND PROTECTIVE DEVICES - annex 1 of machinery directive 2006/42/EC
- Article 1.5. RISKS DUE TO OTHER HAZARDS - annex 1 of machinery directive 2006/42/EC
- Article 1.6. MAINTENANCE - annex 1 of machinery directive 2006/42/EC
- Article 1.7. INFORMATION - annex 1 of machinery directive 2006/42/EC
- Article 2. SUPPLEMENTARY ESSENTIAL HEALTH AND SAFETY REQUIREMENTS - annex 1 machinery directive 2006/42/EC
- Article 3. SUPPLEMENTARY ESSENTIAL HEALTH TO THE MOBILITY OF MACHINERY - annex 1 machinery directive 2006/42/EC
- Article 4. SUPPLEMENTARY REQUIREMENTS TO OFFSET HAZARDS DUE TO LIFTING OPERATIONS of machinery directive 2006/42/EC
- Article 5. SUPPLEMENTARY ESSENTIAL HEALTH AND SAFETY REQUIREMENTS FOR UNDERGROUND WORK of machinery directive 2006/42/EC
- Article 6. SUPPLEMENTARY REQUIREMENTS - HAZARDS DUE TO THE LIFTING OF PERSONS of machinery directive 2006/42/EC
- Annex II : Declarations of CONFORMITY OF THE MACHINERY, DECLARATION OF INCORPORATION - machinery directive 2006/42/EC
- Annex III of machinery directive 2006/42/EC - CE marking
- Annex IV of machinery directive 2006/42/EC
- Annex V of machinery directive 2006/42/EC
- Annex VI of machinery directive 2006/42/EC
- Annex VII - Technical file for machinery - machinery directive 2006/42/EC
- Annex VIII - Assessment of conformity of machinery directive 2006/42/EC
- Annex IX of machinery directive 2006/42/EC - EC type-examination
- Annex X of machinery directive 2006/42/EC - Full quality assurance
- Annex XI of machinery directive 2006/42/EC - Minimum criteria for the notification of bodies
- Annex XII of machinery directive 2006/42/EC - Correlation table between machinery directive 2006/42/CE and MD 1998/37/CE
- Machinery directive 1998/37/EC
- considerings of machinery directive 1998/37/CE
- articles of 1998/37/EC machinery directive
- Annex I of 1998/37/CE machinery directive
- Annex II of 1998/37/EC machinery directive
- Annex III of machinery directive 1998/37/CE
- Annex IV of machine directive 1998/37/EC
- Annex V of machines directive 1998/37/CE
- Annex VI of machines directive 1998/37/EC
- Annex VII of machines directive 1998/37/EC
- Annex VIII of 1998/37/CE machine directive
- Annex IX of machinery directive 1998/37/CE
- Machinery directive 1989/392/EC
- whereas of machinery directive machines 1989/392/EEC
- articles of machinery directive 1989/392/EEC
- Annex I of machinery directive 1989/392/EEC
- Annex II of machine directive 1989/392/EEC
- Annex III of machinery directive 1989/392/EEC
- Annex IV of machinery directive 1989/392/EEC
- Annex V of machinery directive 1989/392/EEC
- Annex VI of machine directive 1989/392/EEC
- Annexe VII of machinery directive 1989/392/EEC
- Amendments of 1989/392/EEC directive
- ATEX directives
- ATEX 94/9/EC directive
- Whereas of ATEX 94/9/CE directive
- Articles of ATEX 94/9/CE directive
- article 1 ATEX 94/9/EC directive
- article 2 ATEX 94/9/EC directive
- article 3 ATEX 94/9/EC directive
- article 4 : ATEX 94/9/EC directive
- article 5 : ATEX 94/9/EC directive
- article 6 : ATEX 94/9/EC directive
- article 7 : ATEX 94/9/EC directive
- article 8 ATEX 94/9/EC directive
- article 9 : ATEX 94/9/EC directive
- article 10 : ATEX 94/9/EC directive
- article 11 : ATEX 94/9/EC directive
- article 12 : ATEX 94/9/EC directive
- article 13 : ATEX 94/9/EC directive
- article 14 : ATEX 94/9/EC directive
- article 15 : ATEX 94/9/EC directive
- article 16 : ATEX 94/9/EC directive
- ANNEX I of ATEX 94/9/EC directive : CRITERIA DETERMINING THE CLASSIFICATION OF EQUIPMENT-GROUPS INTO CATEGORIES
- ANNEX II of ATEX 94/9/EC : directive ESSENTIAL HEALTH AND SAFETY REQUIREMENTS -EHSR
- ANNEX III of ATEX 94/9/EC directive : MODULE EC-TYPE EXAMINATION
- ANNEX IV of ATEX 94/9/EC directive : MODULE PRODUCTION QUALITY ASSURANCE
- ANNEX V of ATEX 94/9/EC directive : MODULE PRODUCT VERIFICATION
- ANNEX VI of ATEX 94/9/EC directive : MODULE CONFORMITY TO TYPE
- ANNEX VII of ATEX 94/9/EC directive : MODULE PRODUCT QUALITY ASSURANCE
- ANNEX VIII of ATEX 94/9/EC directive : MODULE INTERNAL CONTROL OF PRODUCTION
- ANNEX IX of ATEX 94/9/EC directive : MODULE UNIT VERIFICATION
- ANNEX X of ATEX 94/9/EC directive : CE Marking - Content of the EC declaration of conformity
- ANNEX XI of ATEX 94/9/EC directive: NOTIFICATION OF BODIES
- ATEX 99/92/EC Directive
- ATEX DIRECTIVE 2014/34/UE
- whereas of 2014/34/UE ATEX directive
- Articles of ATEX 2014/34/UE directive
- Annex 1 of ATEX 2014/34/UE directive
- Annex 2 of the ATEX 2014/34/UE directive
- Annex 3 of ATEX 2014/34/UE directive
- Annex 4 of ATEX 2014/34/UE directive
- Annex 5 of ATEX 2014/34/UE directive
- Annex 6 of ATEX 2014/34/UE directive
- Annex 7 of ATEX 94/9/EC directive
- Annex 8 of the ATEX 2014/34/UE directive
- Annex 9 of the ATEX 2014/34/UE directive
- Annex 10 of ATEX 2014/34/UE directive
- Annex 11 of ATEX 2014/34/UE directive
- Annex 12 of the ATEX 2014/34/UE directive
- Audits in Ex field - EN 13980, OD 005 and EN ISO/CEI 80079-34
- New ATEX directive
- RASE european project
- ATEX 94/9/EC directive
- IECEX
- Standardization & European Regulation
- Safety of machines : Standardization and European regulations
- European regulation for machines - standardization for machines - harmonized standards
- Standardization in machinery
- EN ISO 12100 - Décembre 2010
- EN ISO 12100-1 - January 2004
- EN ISO 12100-1:2003/A1
- EN ISO 12100-2 November 2003
- EN ISO 12100-2:2003/A1
- EN ISO 14121-1 September 2007
- ISO/TR 14121-2 - 2007
- EN 50205:2002 standard - Relays with forcibly guided (mechanically linked) contacts
- ISO 11161:2007
- ISO 13849-1:2006
- ISO 13849-2:2012
- ISO 13850:2006 - Safety of machinery -- Emergency stop -- Principles for design
- ISO 13851:2002 - Safety of machinery -- Two-hand control devices -- Functional aspects and design principles
- ISO 13854:1996 Safety of machinery - Minimum gaps to avoid crushing of parts of the human body
- ISO 13855:2010 - Safety of machinery -- Positioning of safeguards with respect to the approach speeds of parts of the human body
- ISO 13856-1:2013 Safety of machinery -- Pressure-sensitive protective devices -- Part 1: General principles
- ISO 13856-2:2013 - Safety of machinery -- Pressure-sensitive protective devices -- Part 2: General principles for design testing
- ISO 13856-3:2013 Safety of machinery -- Pressure-sensitive protective devices - Part 3: General principles for design
- ISO 13857:2008 Safety of machinery -- Safety distances to prevent hazard zones
- ISO 14118:2000 - Safety of machinery -- Prevention of unexpected start-up
- ISO 14119:2013- Interlocking devices associated with guards
- ISO 14120:2002 - Guards -- General requirements for the design and construction
- ISO 14122-1:2001 - Permanent means of access to machinery
- ISO 14122-2:2001 - Permanent means of access to machinery
- ISO 14122-4:2004 - Permanent means of access to machinery
- ISO 14123-1:1998 - Reduction of risks to health from hazardous substances emitted by machinery
- ISO 14123-2:1998 - Reduction of risks to health from hazardous substances emitted by machinery
- ISO 14159:2002 - Hygiene requirements for the design of machinery
- ISO 19353:2005 -- Fire prevention and protection
- ISO/AWI 17305 - Safety of machinery - Safety functions of control systems
- ISO/DTR 22100-2 - Safety of machinery -- Part 2: How ISO 12100 relates to ISO 13849-1
- ISO/TR 14121-2:2012 - Risk assessment - Part 2: Practical guidance
- ISO/TR 18569:2004 - Guidelines for the understanding and use of safety of machinery standards
- ISO/TR 23849:2010 - Guidance on the application of ISO 13849-1 and IEC 62061 in the design of safety-related control systems
- STABILITY DATES FOR Machinery STANDARDS
- harmonized standards list - machinery-directive 2006/42/CE
- Publication of harmonised standards for machinery directive 2006/42/EC - 9.3.2018
- Harmonized standard list - machinery directive 2006/42/EC - 9.6.2017
- Harmonized standards for machinery - OJ C 2016/C173/01 of 15/05/2016
- Harmonized standards for machinery -OJ C 2016/C14/102 of 15/01/2016
- Harmonized standards for machinery - corrigendum OJ C 2015/C 087/03 of 13/03/2015
- harmonized standards for machinery - OJ C 2015/C 054/01 of 13/02/2015
- Application guide for machinery directive 2006/42/EC
- Guide to application of the machinery directive 2006/42/CE - July 2017
- Guide to application of the Machinery Directive 2006/42/EC - second edition June 2010
- Guide to application of machinery directive - 1-2 : The citations
- Guide to application of machinery directive - § 3 to § 31 The Recitals
- Guide to application of machinery directive - § 32 to § 156 - The Articles
- Guide to application of machinery directive - § 157 to § 381 - Annex I
- Guide to application of machinery directive - § 382 to § 386 - ANNEX II Declarations
- Guide to application of machinery directive - § 387 - ANNEX III CE marking
- recommendation for use - machinery directive 2006/42/EC
- Notified bodies under the machinery directive 2006/42/CE
- Safety of Ex, ATEX and IECEx equipments : Standardization
- Standardization in Ex Field
- The transposition of the ATEX 94/9/EC Directive to the 2014/34/EU directive
- harmonized standards list - ATEX directive 2014/34/EU
- Harmonized standard list for ATEX 2014/34/UE - 12-10-2018
- Harmonized standard list for ATEX 2014/34/UE - 15.6.2018
- Harmonized standard list for ATEX 2014/34/UE - 12-07-2019
- Harmonized standard list for ATEX 2014/34/UE - 9.6.2017
- Harmonized standards list ATEX 2014/34/UE directive - OJ C 126 - 08/04/2016
- Guide to application of the ATEX Directive 2014/34/EU
- application guide of 2014/34/EU directive - preambule, citations and recitals
- Guide to application of the ATEX 2014/34/UE directive - THE ARTICLES OF THE ATEX DIRECTIVE
- Guide to application of the ATEX 2014/34/UE directive - ANNEX I CLASSIFICATION INTO CATEGORIES
- Guide to application of the ATEX 2014/34/UE directive - ANNEX II ESSENTIAL HEALTH AND SAFETY REQUIREMENTS
- Guide to application of the ATEX 2014/34/UE directive - ANNEX III MODULE B: EU-TYPE EXAMINATION
- Guide to application of the ATEX 2014/34/UE directive - ANNEX IV MODULE D: CONFORMITY TO TYPE
- Guide to application of machinery directive - § 388 - ANNEX IV machinery and mandatory certification
- Guide to application of the ATEX 2014/34/UE directive - ANNEX V MODULE F: CONFORMITY TO TYPE
- Alignment of ten technical harmonisation directives - Decision No 768/2008/EC
- ATEX 94/9/EC directive documents
- ATEX 94/9/EC guidelines
- ATEX 94/9/EC guidelines 4th edition
- 1 INTRODUCTION of ATEX 94/9/EC guidelines 4th edition
- 2 OBJECTIVE OF THE ATEX DIRECTIVE 94/9/EC - ATEX 94/9/EC guidelines 4th edition
- 3 GENERAL CONCEPTS of ATEX 94/9/EC directive ATEX 94/9/EC guidelines 4th edition
- 4 IN WHICH CASES DOES DIRECTIVE 94/9/EC APPLY - ATEX 94/9/EC guidelines 4th edition
- 5 EQUIPMENT NOT IN THE SCOPE OF DIRECTIVE 94/9/EC - ATEX 94/9/EC guidelines 4th edition
- 6 APPLICATION OF DIRECTIVE 94/9/EC ALONGSIDE OTHERS THAT MAY APPLY - ATEX 94/9/EC guidelines 4th edition
- 7 USED, REPAIRED OR MODIFIED PRODUCTS AND SPARE PARTS - ATEX 94/9/EC guidelines 4th edition
- 8 CONFORMITY ASSESSMENT PROCEDURES - ATEX 94/9/EC guidelines 4th edition
- 9 NOTIFIED BODIES - ATEX 94/9/EC guidelines 4th edition
- 10 DOCUMENTS OF CONFORMITY - ATEX 94/9/EC guidelines 4th edition
- 11 MARKING - CE marking -ATEX 94/9/EC guidelines 4th edition
- 12 SAFEGUARD CLAUSE AND PROCEDURE - ATEX 94/9/EC guidelines 4th edition
- 13 EUROPEAN HARMONISED STANDARDS - ATEX 94/9/EC guidelines 4th edition
- 14 USEFUL WEBSITES - ATEX 94/9/EC guidelines 4th edition
- ANNEX I: SPECIFIC MARKING OF EXPLOSION PROTECTION - ATEX 94/9/EC guidelines 4th edition
- ANNEX II: BORDERLINE LIST - ATEX PRODUCTS - ATEX 94/9/EC guidelines 4th edition
- ATEX 94/9/EC guidelines 4th edition
- Harmonized standards list - ATEX 94/9/EC directive
- Harmonized standards list ATEX 94/9/EC directive - OJ C 126 - 08/04/2016
- Harmonized standards list ATEX 94/9/EC - OJ C 335 - 09/10/2015
- Harmonized standards list ATEX 94/9/EC - OJ-C 445-02 - 12/12/2014
- Harmonized standards list ATEX 94/9/EC - OJ-C 076-14/03/2014
- Harmonized standards list ATEX 94/9/EC - OJ-C 319 05/11/2013
- ATEX 94/9/EC guidelines
- European regulation for ATEX 94/9/EC ATEX directive
- Guide to application of ATEX 2014/34/EU directive second edition
- Safety of machines : Standardization and European regulations
- Latest news & Newsletters
- Functional safety
- Terms and definitions for functional safety
- Safety devices in ATEX
- The SAFEC project
- main report of the SAFEC project
- Appendix 1 of the SAFEC project - guidelines for functional safety
- Appendix 2 of the SAFEC project
- ANNEX A - SAFEC project - DERIVATION OF TARGET FAILURE MEASURES
- ANNEX B - SAFEC project - ASSESSMENT OF CURRENT CONTROL SYSTEM STANDARDS
- ANNEX C - safec project - IDENTIFICATION OF “USED SAFETY DEVICES”
- Annex D - SAFEC project - study of ‘ Used Safety Devices’
- Annex E - Determination of a methodology for testing, validation and certification
- EN 50495 standard for safety devices
- The SAFEC project
- Safety components in Machinery
- STSARCES - Standards for Safety Related Complex Electronic Systems
- STSARCES project - final report
- STSARCES - Annex 1 : Software engineering tasks - Case tools
- STSARCES - Annex 2 : tools for Software - fault avoidance
- STSARCES - Annex 3 : Guide to evaluating software quality and safety requirements
- STSARCES - Annex 4 : Guide for the construction of software tests
- STSARCES - Annex 5 : Common mode faults in safety systems
- STSARCES - Annex 6 : Quantitative Analysis of Complex Electronic Systems using Fault Tree Analysis and Markov Modelling
- STSARCES - Annex 7 : Methods for fault detection
- STSARCES - Annex 8 : Safety Validation of Complex Components - Validation by Analysis
- STSARCES - Annex 9 : safety Validation of complex component
- STSARCES - Annex 10 : Safety Validation of Complex Components - Validation Tests
- STSARCES - Annex 11 : Applicability of IEC 61508 - EN 954
- STSARCES - Annex 12 : Task 2 : Machine Validation Exercise
- STSARCES - Annex 13 : Task 3 : Design Process Analysis
- STSARCES - Annex 14 : ASIC development and validation in safety components
- Functional safety in machinery - EN 13849-1 - Safety-related parts of control systems
- STSARCES - Standards for Safety Related Complex Electronic Systems
- History of standards for functional safety in machinery
- Basic safety principles - Well-tried safety principles - well tried components
- Functional safety - detection error codes - CRC and Hamming codes
- Functional safety - error codes detection - parity and chechsum
- Functional safety and safety fieldbus
- ISO 13849-1 and SISTEMA
- Prevention of unexpected start-up and machinery directive
- Self tests for micro-controllers
- Validation by analysis of complex safety systems
- basic safety principles - safety relays for machinery
- Download center
- New machinery regulation
- Revision of machinery directive 2006/42/EC
- security for machines
Functional safety - error codes detection - parity and chechsum
Description of error detection codes and error correction codes
The Hamming distance and the residual error rates are different for all methods that allows to detect and to correct these transmission errors. Coding methods that are be presented in the first part of this paper are:
- error detection codes by parity
- error detection code method by CHECKSUM
- error detection codes by CRC
- Detectors codes and error correcting codes by HAMMING
The first two methods are described below. CRC and detectors / error correcting codes are described in another article
1 Parity
1.1.Principle of the parity
This is a modulo-2 sum of information bits.
- Parity is said even when the parity code equals to the sum modulo 2 of the information bits
- Parity is said odd when parity code is equal to the complement of that.sum
This method of control is used in the RS-232 series transmission and in microprocessors.
Before each transmission of a word, an extra digit added. It is called a parity bit. After transmission, the presence of a simple error change the parity value and makes the error detectable .
1.2.Détection of errors - Residual Errors
If we call 'p' the probability of individual error of a single digit, and "n" the word length.
The probability of having a single error is
P(1) = P[1st digit wrong and the (n-1 following digit) valid] + P[1st digit valid and 2nd digit false and the (n-2 following digits) valid] + ...
P(1) = p(1-p)n-1 + (1-p)p(1-p)n-2 + (1-p)2p(1-p)n-2 + ...
P(1) = n[p(1-p)n-1]
Similarly we obtain:
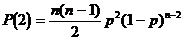
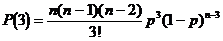
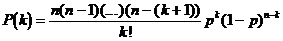
Parity can detect all odd errors with a power of detection PD that is :
PD = P(1) + P(3) + ... + P(2k-1)
Undetected errors are all even errors so a power not to detect failure PND:
PND = P(2) + P(4) + ... + P(2k)
These numbers are a function of p, and must be calculated depending of environments.
Assuming that we have a frame consisting of 8 data bits of information and a key verification by parity bit (n = 9). By changing an even number of bits e = {2, 4, 6, 8} in the frame we have another frame in which errors are not detected by the verification key.
The residual error rate can be calculated in accordance with the information provided on page http://www.industry-finder.com/machinery-directive/functional-safety-and-safety-fieldbus.html, and the probability of residual error is equal to the sum of the even errors :
which is :
R = R1*R2
with : R1=P(2)+P(4)+P(6)+P(8) - the probability of error on the datagiven on
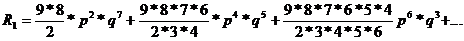
R2 = probability that the frame delimiters are correct. In the case of single-parity, we have two delimiters (start and end of frame) and a probability q * q = q2
Either:
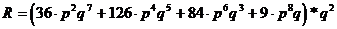
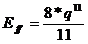
2. The CHECKSUM
There are several methods used to achieve a CHECKSUM such as:
- The method of the modified sum control,
- The arithmetic addition of the contents of the message,
- Parity Codes interleaved .
This last method will be detailled.
2.1.Principle of the CHECKSUM
The principle of parity code interleaved CHECKSUM is a message M digits, written in the form of an array of "L" lines and "C" column (M = CL). In this table, is added (L + 1) th row and a (C + 1) th column constructed such that the words that are read horizontally and vertically are even.
The method then determines the number of "1" contained in a row (column). If this number is even, is assigned to the intersection of that line (column) and the last column (row), the state "0" or "1" if the number is odd. This operation is performed for each row and each column. The digit located at the crossroads of the last row and the last column is selected to ensure parity of the entire message.
For example, a message M = 49 digits (7 words of 7 bit):
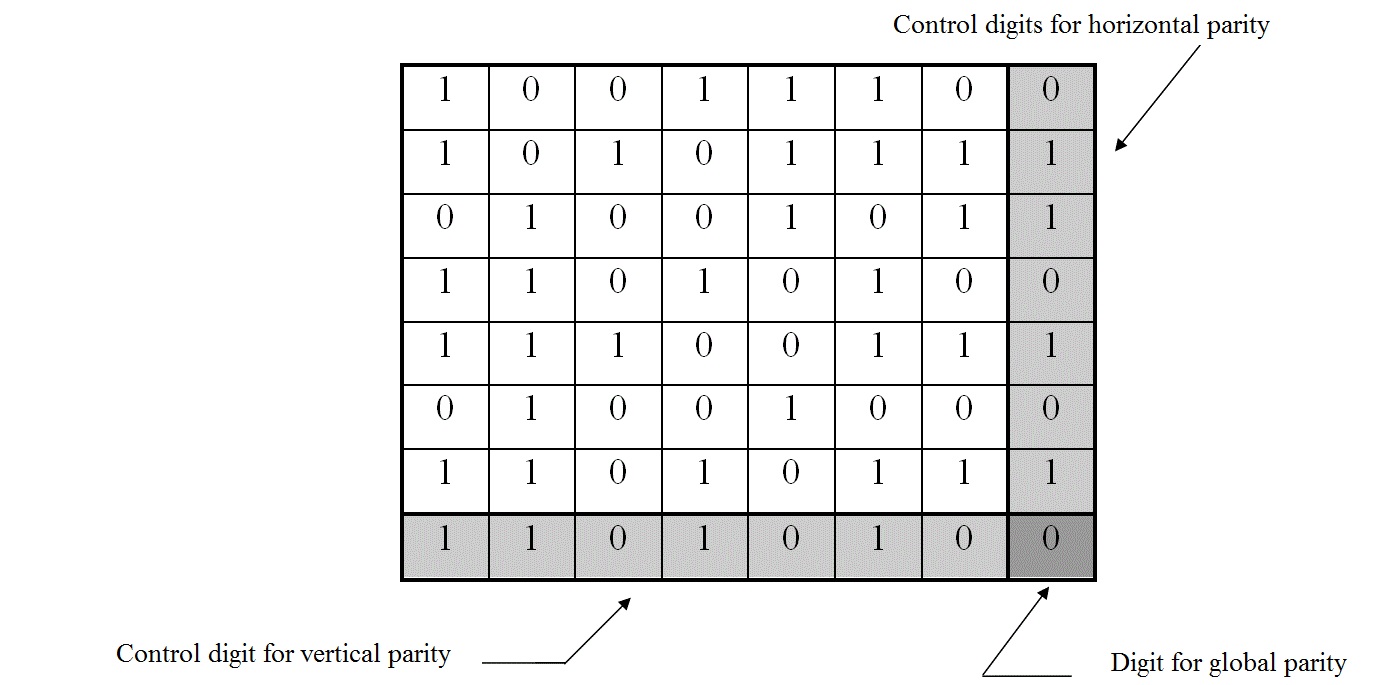
A set of 64 digits (49 digits for the transmittion of the informationand 15 digits reserved to the control) is transmitted and received in series in the transmission channel. At the reception, the table is restored. Only one mistake can make the parity check of the line and the corresponding column, therefore, detection and correction are possible.
A double or quadruple error is detected but can not be corrected, the triple error is not always detected.
This code is more powerful than parity but requires additional hardware resources. A message which originally M digits (M = CL) requires C + L + 1 check digits, so an increase or redundancy DR:
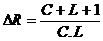
For 7 data bits, M = 49 DR = 15/49 = 0.31
For 15 bits of information, M = 225 DR = 31/225 = 0.14
2.2.Detection coverage of a CHECKSUM - Residual Errors
The power detection/coverage of a CHECKSUM is calculated differently depending on the number of bytes, first from a main method or from a probabilistic method.
2.2.1.Main Méthode
This method is is based an accurate count of all combinations of "N" words "P" bits of a sequence of information leading to an amount equal to the sum "S" obtained on the "N" word of the sequence containing the original information.
The theoretical power of detection P D is defined as the ratio (expressed as a percentage) between the number of detected errors NDET by the control and the total number of errors NTOT that can occur on the sequence of information to control.
The expression of the total number of errors NTOT represents the number of combinations that can take the (P x N) bits of the sequence to control, which gives for N bytes:
N TOT = 2 PN
The determination of the number NDET or of the number of undetected errors NNDET where NDET + NNDET = 2P.N
NNDET correspond to the number 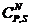 of combinations of "N" bytes whose sum is identical to the sum "S" obtained on the bytes of the sequence of information in the absence of errors.
of combinations of "N" bytes whose sum is identical to the sum "S" obtained on the bytes of the sequence of information in the absence of errors.
The power of detection can then be expressed as follows:
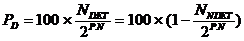
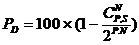
Calculations that performs enumeration of all combinations of "N" bytes of an information sequence whose sum is "S" leads to the following formulas:
for S = 0; 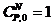 ; P = 8 bits (the number of bits in a byte)
; P = 8 bits (the number of bits in a byte)
PD = 100 x (1-1/28.N) » 100 %
for S 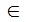 [ k (2P - 1),(k+1) (2P - 1)] with
[ k (2P - 1),(k+1) (2P - 1)] with
integer k [ 0 , N-1-INT(N/2P)]
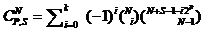 0! = 1
0! = 1
where 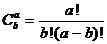
Numerical calculation is possible only for small values of N (N <40). Beyond this level, it is necessary to use the "probabilistic" method.
2.2.2."Probabilistic Method"
With the "probabilistic method", each byte may be considered as a random variable. A given configuration is the sequence of "N" corresponding random variables.
Considering that the probability distribution is the same for each byte (average value m, variance s 2), where "N" is large (N> 50), the distribution of the sum "S" of random variables is very substantially normal (follow the normal law used in statistics), average value Nm and variance Ns2 and there the probability that the sum of "N" variable is equal to a value "s":
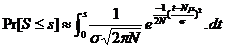
The probabilité of an entire value « s » is :
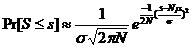
with 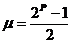 and
and 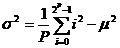
The probability is maximum for the Nm value of "s":
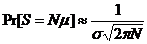
Applied to memories of 8-bit data size (P = 8) and for a given data capacity, we get the following results:
For P = 8
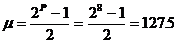 and
and 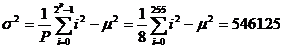
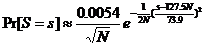 and
and 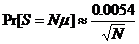
For:
N = 512 o Pr[ S = 65280 ] ~ 0.0002386 (99.976 %)
N = 16 ko Pr[ S = 2088960 ] ~ 0.000042 (99.9958 %)
N = 1 ko Pr[ S = 130560 ] ~ 0.0001688 (99.983 %)
N = 32 ko Pr[ S = 4177920 ] ~ 0.0000298 (99.997 %)
English
